This notebook is a practical demonstration of an exploratory data analysis task. For this task, we want to understand how completion rates differ for different types of students and different types of schools. We want to look at this by:
- Student race
- Admission policy and rate
- Public/private status (the documentation describes this as “control” — what is the legal or financial control status of the school?)
We will work with the data set underlying the Department of Education’s College Scorecard. This is a medium-sized data set. We will only work with the most recent cohort’s data.
Motivation.¶
The data was created to promote openness by giving students and families the ability to assess different colleges are preparing performing and preparing its students for the workforce. The public, particularly students and families can use the data to compare the costs and results of various universities.
The instituition data is part of the large College Scoredcard project of the U.S Department of Education. The data is collected annually through surveys administered by the Department of Education’s National Center for Education Statistics (NCES), IPEDS is the primary source of data on postsecondary education institutions in the United States.
Composition¶
There are about 10 instances in the data:
- Academics : This instance describes the types of academic offerings available at each institution.
- Admissions : This instance This information describes the admissions rate and SAT/ACT scores of students aids.
- Aid : This instance covers information on financial aid including Pell Grants and federal student loans which help many students particularly low-incone students access and afford a higher education.
- Completion : This instance contains information on college completion which determines other positive outcones such as finding a job and succesfully repaying student loans.
- Cost : This instance contains information about the costs to students of an institution which can provide important context for students and families as they seek to evaluate the tradeoffs of access, affordability, and outcomes.
- Earnings : This instance contains information on the earnings and employment prospects of former students.
- Repayment : This instance provides information on the debt burden of attending college and the loan performance metrics for each institution.
- School : This instance provides basic descriptive information about the institution in question. These include: identifiers, location, degree type and profile, programs offered, and the academic profile of students enrolled.
- Student : This instance identifies demographic and other details about the student body of the institution. The category under this include number of undergraduate students, student body by race, gender, age, Part-Time/Full-Time status, family income
Q4: Does the dataset identify any subpopulations (e.g., by age, gender)? If so, please describe how these subpopulations are identified and
provide a description of their respective distributions within the dataset.
Yes. The instituitional data contains several elements that identify demographic based on their age, sex and race. The race and gender are reported by the instituitions to IPEDS in the fall enrollment components and rely on student’s self-reported race and gender data as collected by the instituition.
#import packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
0. Data Cleaning¶
read the data¶
# read the csv file
schools = pd.read_csv('../../Data/Most-Recent-Cohorts-Institution_04262022/Most-Recent-Cohorts-Institution.csv',
usecols= ['INSTNM', 'CITY', 'STABBR', 'ST_FIPS', 'CONTROL', 'HIGHDEG', 'ICLEVEL', 'C150_4', 'C150_4_POOLED', 'C150_L4', 'C150_L4_POOLED', 'C100_4', 'C100_4_POOLED', 'C100_L4', 'C100_L4_POOLED',
'OPENADMP', 'ADM_RATE', 'ADM_RATE_ALL'])
#create a dictionary variable to use for encoding ST_FIPS column
state_name = {1: 'Alabama', 2 : 'Alaska', 4 : 'Arizona', 5 : 'Arkansas', 6 : 'California', 8 : 'Colorado', 9 : 'Connecticut', 10 : 'Delaware',
11 : 'District of Columbia', 12 : 'Florida', 13 : 'Georgia', 15 : 'Hawaii', 16 : 'Idaho', 17 : 'Illinois', 18 : 'Indiana', 19 : 'Iowa', 20 : 'Kansas',
21: 'Kentucky', 22 : 'Louisiana', 23 : 'Maine', 24 : 'Maryland', 25 : 'Massachusetts', 26 : 'Michigan', 27 : 'Minnesota', 28 : 'Mississippi', 29 : 'Missouri', 30 : 'Montana',
31 : 'Nebraska', 32 : 'Nevada', 33 : 'New Hampshire', 34 : 'New Jersey', 35 : 'New Mexico', 36 : 'New York', 37 : 'North Carolina', 38 : 'North Dakota', 39: 'Ohio', 40 : 'Oklahoma',
41 : 'Oregon', 42 : 'Pennsylvania', 44 : 'Rhode Island', 45 : 'South Carolina', 46 : 'South Dakota', 47 : 'Tennessee', 48 : 'Texas', 49 : 'Utah', 50 : 'Vermont',
51 : 'Virginia', 53 : 'Washington', 54 : 'West Virginia', 55 : 'Wisconsin', 56 : 'Wyoming', 60 : 'American Samoa', 64 : 'Federated States of Micronesia', 66 : 'Guam',
69 : 'Northern Mariana Islands', 70 : 'Palau', 72 : 'Puerto Rico', 78 : 'Virgin Islands'}
# encode ST_FIPS to the state name and drop the column
schools['STATE'] = schools.ST_FIPS.map(state_name)
schools = schools.drop(['ST_FIPS'], axis = 1)
# create a dictionary variable to use for encoding CONTROL
control_name = {1 : 'Public', 2 : 'Private, Nonprofit', 3 : 'Proprietary'}
# encode CONTROL column and drop the column
schools['CONTROL_STATUS'] = schools.CONTROL.map(control_name)
schools = schools.drop(['CONTROL'], axis = 1)
# create a dictionary to use for encoding Highest award column
highdegree_name = {0 : 'Non-degree-granting', 1: 'Certificate degree', 2 : 'Associate degree', 3 : 'Bachelor degree' , 4 : 'Graduate degree'}
# encode HIGHDEG column and drop the column
schools['HIGHDEG_TYPE'] = schools.HIGHDEG.map(highdegree_name)
schools = schools.drop(['HIGHDEG'], axis = 1)
# create a dictionary to use for encoding Level of Instituition
iclevel_name = {1 : '4 Year', 2 : '2 Year', 3 : 'Less than 2 year'}
# encode ICLEVEL column and dropm the column
schools['ICLEVEL_TYPE'] = schools.ICLEVEL.map(iclevel_name)
schools = schools.drop(['ICLEVEL'], axis= 1)
schools
# check the data structure
schools.info()
Fill in the missing values¶
There are lot of missing values in the completion rate columns as shown by the info above. There are about 6662 records of instuitions in the database but the completion rate variables have way less. For example, C150_4 has 2270 non-null values while C150_L4 has about 3180. A way to fill the missing values is to combine these columns if there are no schools in both categories.
#find out if there is any school in both 4 years and less than 4 years column
print(len(schools[schools['C100_4'] == schools['C100_L4']]))
print(len(schools[schools['C150_4'] == schools['C150_L4']]))
#Filling the 4 years column with less than 4 years column
schools['C_100'] = schools['C100_4'].combine_first(schools['C100_L4'])
schools['C_100_POOLED'] = schools['C100_4_POOLED'].combine_first(schools['C100_L4_POOLED'])
schools['C_150'] = schools['C150_4'].combine_first(schools['C150_L4'])
schools['C_150_POOLED'] = schools['C150_4_POOLED'].combine_first(schools['C150_L4_POOLED'])
#drop the other completion rate columns after filling
schools = schools.drop(['C100_4', 'C100_L4', 'C100_4_POOLED', 'C100_L4_POOLED', 'C150_4', 'C150_L4', 'C150_4_POOLED', 'C150_L4_POOLED'], axis = 1)
schools.info()
Selecting Variables¶
The completion rates for full-time, first-time students who complete within 100 or 150 percent of the expected time to completion are represented by C_100 and C_150 variables respectively. However, only the 150 percent rates are available disaggregated by race. So C_150 would make the most of sense in the context of this task. C_100_POOLED and C_150_POOLED variables are pooled completion rates across two years rolling basis. For self-consistent analysis, I use the normal completion rate variables and not the pooled varaibles.
#drop the POOLED completion rates
schools = schools.drop(['C_100_POOLED', 'C_150_POOLED'], axis = 1)
schools.info()
ADMISSIONS¶
There are two variables that describe the admissions practices. OPENADMP indicates whether it has an open admissions policy. 1 -Yes, 2 – No, 3 – Does not enrol first-time student. Second, schools that do not have an open admissions policy (2) report the admission rate. For institutions with multiple branches,
ADM_RATE includes the admissions rate at each campus, while ADM_RATE_ALL represents the admissions rate across all campuses.
We’re going to bucketize the admissions policy. I defined three categories of schools:
- Open-admission schools
- Low-selectivity schools, where the admission rate is higher than the median admission rate
- High-selectivity schools, where the admission rate is lower than the median admission rate
# calculate the median admission rate for ADM_RATE and ADM_RATE_ALL
adm_median = schools['ADM_RATE'].median()
adm_median_all = schools['ADM_RATE_ALL'].median()
print(adm_median)
print(adm_median_all)
#Convert admission rate to categorical values
# Bucketize the ADM_RATE variable
schools['ADM'] = 'Open-admission'
schools.loc[schools['ADM_RATE'] < adm_median, 'ADM'] = 'High-selectivity'
schools.loc[schools['ADM_RATE'] > adm_median, 'ADM'] = 'Low-selectivity'
#Bucketize the ADM_RATE_ALL variable
schools['ADM_ALL'] = 'Open-admission'
schools.loc[schools['ADM_RATE_ALL'] < adm_median_all, 'ADM_ALL'] = 'High-selectivity'
schools.loc[schools['ADM_RATE_ALL'] > adm_median_all, 'ADM_ALL'] = 'Low-selectivity'
schools
TASK REQUIREMENT¶
1. A basic structural description of the data set:¶
- How many schools and variables?
- How many schools are there per state?
- How are schools-per-state distributed? Compute a state-level variable ‘# of schools’, and describe its distribution numerically and visually.
schools
schools['INSTNM'].nunique()
There are about 6530 schools
schools.groupby('STATE')['INSTNM'].count()
The dataframe above shows the number of schools per state.
num_schools = schools.groupby('STATE')['INSTNM'].count()
# convert the series to dataframe
num_schools = num_schools.to_frame().reset_index()
#rename the column
num_schools = num_schools.rename(columns={"INSTNM": "COUNT"})
num_schools
num_schools.describe()
num_schools.plot.bar(x = 'STATE', y = 'COUNT', figsize=(18,10))

There is median of 81 schools in the states. Atleast one school in each state. California has the highest number of schools (705).
2. The distribution of the overall completion rate:¶
- Provide choice of completion rate variable with a justification for that choice.
- Describe the distribution of that variable numerically and visually.
- What is the mean? Is the distribution skewed?
I selected C_100 and C_150 as the completion rates. The rational for this has been explained in the selection of variable section above.
schools
com = schools[['C_100', 'C_150']]
com
com.describe()
plt.hist(com['C_100'], bins = 20)

plt.hist(com['C_150'], bins = 20)

sns.set(style="darkgrid")
sns.boxplot(data=com.loc[:, ['C_100', 'C_150']])
plt.show()

More students completed in 150% of expected time of completion than 100%. The mean completion rate is 0.37 and 0.56 for C_100 and C_150 respectively. C_100 is slightly left skewed while C_150 is normally distributed.
3. The distribution of the admission rate, both numerically and graphically¶
After describing the distribution of the continuous admission rate, compute the admissions category (open, low-selectivity, or high-selectivity). Do not hard-code the median — compute the median, and use the computed value (stored in a Python variable) to bucketize the admission rates. Show the distribution of admissions category (how many schools are in each category?).
adm = schools[['ADM_RATE', 'ADM']]
adm.describe()
plt.hist(adm['ADM_RATE'], bins = 20)

The mean admission rate is 0.71 and it is right skewed. I have bucketized the admnission rate in the data data section
plt.hist(adm['ADM'])

About 1000 schools are in low-selectivity and high-selectivity category and 5000 are in open-admission category
4. The break down (sometimes called a disaggregation) of completion rate by race, by the school characteristics described in “Question”, and by one additional school characteristic you select.¶
Give a justification for your choice of additional characteristic — why do you think it might be interesting?
You need to show these breakdowns both numerically and graphically. Box plots are useful for this, as are bar charts.
# read the csv file and select the completion rates by race
rate_race_4 = pd.read_csv('../../Data/Most-Recent-Cohorts-Institution_04262022/Most-Recent-Cohorts-Institution.csv',
usecols= ['INSTNM' ,'C150_4_WHITE', 'C150_4_BLACK', 'C150_4_HISP', 'C150_4_ASIAN', 'C150_4_AIAN', 'C150_4_NHPI', 'C150_4_2MOR', 'C150_4_NRA', 'C150_4_UNKN'])
# read the csv file and select the completion rates by race
rate_race_L4 = pd.read_csv('../../Data/Most-Recent-Cohorts-Institution_04262022/Most-Recent-Cohorts-Institution.csv',
usecols= ['INSTNM', 'C150_L4_WHITE', 'C150_L4_BLACK', 'C150_L4_HISP', 'C150_L4_ASIAN', 'C150_L4_AIAN', 'C150_L4_NHPI', 'C150_L4_2MOR', 'C150_L4_NRA', 'C150_L4_UNKN'])
rate_race_4.info()
rate_race_L4.info()
From the two info dataframes above, we see that there are missing values for the completion rate by race records. For example, of the 6k records, there are 2143 records for completion rates of white race at 4 year (C150_4_WHITE) and 1516 records for C150_L4_WHITE. Let’s combine these values since we have earlier confirmed that there is no instutuition that appear in both columns. For this combination, I write a for loop that iterates over each race column and perform the combination. The combined race is stored in a varible determined by the last string of the race column. For example, ‘C150_4_WHITE’ and ‘C150_L4_WHITE’ are combined to ‘WHITE’. Then I dropped the columns that appropriate columns after combining. This is done in the next code cells
for i in range(rate_race_4.shape[1]):
if i > 0:
#print(rate_race_4.columns[i])
rate_race_4[rate_race_4.columns[i].split('_')[2]] = rate_race_4[rate_race_4.columns[i]].combine_first(rate_race_L4[rate_race_L4.columns[i]])
rate_race = rate_race_4.drop(['C150_4_WHITE', 'C150_4_BLACK', 'C150_4_HISP', 'C150_4_ASIAN', 'C150_4_AIAN', 'C150_4_NHPI', 'C150_4_2MOR', 'C150_4_NRA', 'C150_4_UNKN'], axis = 1)
rate_race.info()
As shown in the info dataframe above, white now has 3359 record which is the combination of records in ‘C150_4_WHITE’ and ‘C150_L4_WHITE’
rate_race.describe()
Let’s plot the histogram for the completion rate and the box plot based on race
rate_race.plot.hist(subplots=True, layout = (2, 5), figsize=(18,12))
plt.tight_layout()
plt.show()

rate_race.boxplot(column = ['WHITE', 'BLACK', 'HISP', 'ASIAN', 'AIAN', 'NHPI', '2MOR', 'NRA', 'UNKN'], figsize=(18,12))
plt.show()

The mean completion rate is lowest for BLACK and highest for ASIAN. For completion rates by selectivity. I have already bin the admission rates into three class in the schools dataframe
rate_selectivity = schools[['INSTNM', 'STATE', 'C_100', 'C_150', 'ADM']]
rate_selectivity
Let’s group by selectivity classes and compute the completion stats with the group
rate_selectivity.groupby('ADM')['C_100'].agg(['mean', 'count'])
# set a grey background (use sns.set_theme() if seaborn version 0.11.0 or above)
sns.set(style="darkgrid")
sns.boxplot(x= rate_selectivity["ADM"], y=rate_selectivity["C_100"])
plt.show()

rate_selectivity.groupby('ADM')['C_150'].agg(['mean', 'count'])
sns.set(style="darkgrid")
sns.boxplot(x= rate_selectivity["ADM"], y=rate_selectivity["C_150"])
plt.show()

Open admission schools have low median completion rate than low selectivity and high-selectivity. High-selectivity has the highest completion rate.
For completion rate by CONTROL
rate_control = schools[['INSTNM', 'STATE', 'C_100', 'C_150', 'CONTROL_STATUS']]
rate_control
rate_control.groupby('CONTROL_STATUS')['C_100'].agg(['mean', 'count'])
# set a grey background (use sns.set_theme() if seaborn version 0.11.0 or above)
sns.set(style="darkgrid")
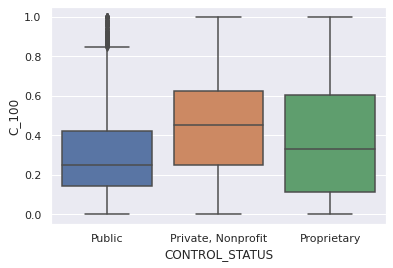
sns.boxplot(x= rate_control["CONTROL_STATUS"], y= rate_control["C_100"])
plt.show()

The boxplot shows that private instituitions has higher median completion rate than public instituition
# set a grey background (use sns.set_theme() if seaborn version 0.11.0 or above)
sns.set(style="darkgrid")
sns.boxplot(x= rate_control["CONTROL_STATUS"], y= rate_control["C_150"])

The addition school characteristics that I choose is the DEGREE TYPE. The rational behind this choise is that the higher the degree, the more challenging it becomes to complete
rate_highdegree = schools[['INSTNM', 'STATE', 'C_100', 'C_150', 'HIGHDEG_TYPE']]
rate_icleveltype = schools[['INSTNM', 'STATE', 'C_100', 'C_150', 'ICLEVEL_TYPE']]
# set a grey background (use sns.set_theme() if seaborn version 0.11.0 or above)
sns.set(style="darkgrid")
sns.boxplot(x= rate_highdegree["HIGHDEG_TYPE"], y= rate_highdegree["C_100"])
plt.show()

# set a grey background (use sns.set_theme() if seaborn version 0.11.0 or above)
sns.set(style="darkgrid")
sns.boxplot(x= rate_icleveltype["ICLEVEL_TYPE"], y= rate_icleveltype["C_100"])
plt.show()

# set a grey background (use sns.set_theme() if seaborn version 0.11.0 or above)
sns.set(style="darkgrid")
sns.boxplot(x= rate_icleveltype["ICLEVEL_TYPE"], y= rate_icleveltype["C_150"])
plt.show()

Based on the boxplot above, less than 2 years degree has higher completion rates than 4 years degress

