This notebook contains basic demonstration of how to explore and describe dataset with pandas. The basic outcomnes for this include:
- importing python libraries
- Load a data file into pandas
- Examine the size and data types of a dataframe
- Understand the relationship between DataFrame, Series and Index
- Compute aggreate values from a pandas series
- Compute grouped aggregrate values from a pandas dataframe
- Order a data frame
- Join two pandas dataframes for additional context
- Provide numerical descriptions of a distribution
- Visualize the distribution of a variable
Dataset¶
For this notebook, I used the MovieLens 25M Dataset. The Zip file is 250MB, and the files take about 1.2GB uncompressed. A quick documentation for the dataset is available here
Python modules¶
Most useful python functions are in modules. In other to use them, they need to be first imported
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
Reading CSV¶
movies = pd.read_csv('../Data/ml-25m/movies.csv')
movies
The DataFrame¶
movies.info()
- RangeIndex: indexes 0 to n-1
- 3 columns
- 1
int64 - 2
object– these store strings
- 1
- 62423 rows
- Kind of data
- integer moviedID
- string title
- string genres
- The data is about movies
-Each column is a series. It can be accessed like a disctionary
Series¶
- An array with an index
- All columns of the dataFrame share the same index
movies['title']
# How big is the series?
from turtle import title
print(movies['title'].size)
print(len(movies['title']))
print(movies['title'].shape)
#count count values not including missing values
movies['title'].count()
- .shape returns the array shape as a tuple — the array is one-dimensional with length 25M
- .size returns the series size (length). len(…) is identical.
- .count() counts values, not including missing value
Another DataFrame¶
Let’s load the ratings
ratings = pd.read_csv('../Data/ml-25m/ratings.csv')
ratings.info()
- Data has about 25M instances
- Data contains
- userId(int)
- movieId(int)
- rating(float)
- timestamnp(int)
ratings
Aggregrate Functions¶
An aggregate function combines a series (or array) into a single value:
ratings['rating'].mean()
ratings['rating'].sum()
Alternate form – function from numpy
np.sum(ratings['rating'])
Quantiles¶
Let’s see the quantile function
ratings['rating'].quantile(0.25)
ratings['rating'].quantile(0.75)
Interesting. 25% of the ratings is 4 or greater
Grouped Aggregrates¶
We can group by a column and compute aggreagrates within the group.
How many ratings per movie?
ratings.groupby('movieId')['rating'].count()
We can compute multiple aggregates at the same time:
movie_stats = ratings.groupby('movieId')['rating'].agg(['mean', 'count'])
movie_stats
Finding Largest¶
We can get the 10 movies with the most ratings and 10 most rated movie
movie_stats.nlargest(10, 'count')
movie_stats.nlargest(10, 'mean')
Linking Data¶
Data can refer to other data
- Ratings are instances themselves
- But each connects a user to a movie
We can merge the two.
We want to combine our stats with movie info.
- on=’movieId’ says to use the movieId column of the first frame instead of its index.
- Matches values to index in other frame
movie_info = movies.join(movie_stats, on='movieId')
movie_info
movie_info.nlargest(10, 'count')
Average Movie Rating¶
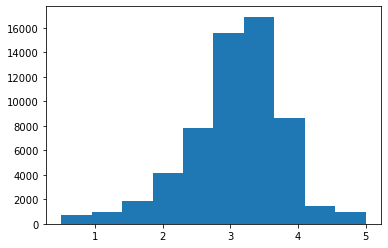
let’s look at the distribution of average movie rating:
movie_info['mean'].describe()
Let’s make a histogram:
plt.hist(movie_info['mean'])
plt.show()

And with more bins:
plt.hist(movie_info['mean'], bins=50)
plt.show()

Wrapping Up¶
- A dataframe consists of columns
- Each column is a series: array with index
- We can call info() method to quickly see
- how many rows (instances)
- what columns
- data types
- Aggregrates combine a series or array into a single value
- Can compute over a whole series or over groups
- Join combines frames
- data description can be presented numerically and visually

